
Kafka messages are eternal
Kafka is wonderful tool for building event driven systems and it's becoming more and more popular every year. Many companies use Kafka as just message bus, but some use Kafka as source-of-truth for event sourced platforms.
If you are playing with event sourcing, there is a good chance that you have topics that have very long retention time - maybe months or more. It means that the message once pushed to the topic will be there for a while, because your application will consume messages from a topic many times. I won't go into details, but key idea of event sourcing is keeping the history (in the correct order) of all changes applied to some object, let's say - contents of shopping cart.
The funny fact about Kafka is that if you push a message to a topic, the message will stay there unchanged, because messages in Kafka are immutable. That's fine, right? No one will mess with your history. But wait, if no one can change messages and your topic will keep them for months or even years, then what happens - just theoretically - if a tired, not properly focused developer in a rush will push a faulty message to a topic? Or let's say, there is a bug in the producer code and the service emits valuable data, but in incorrect format.
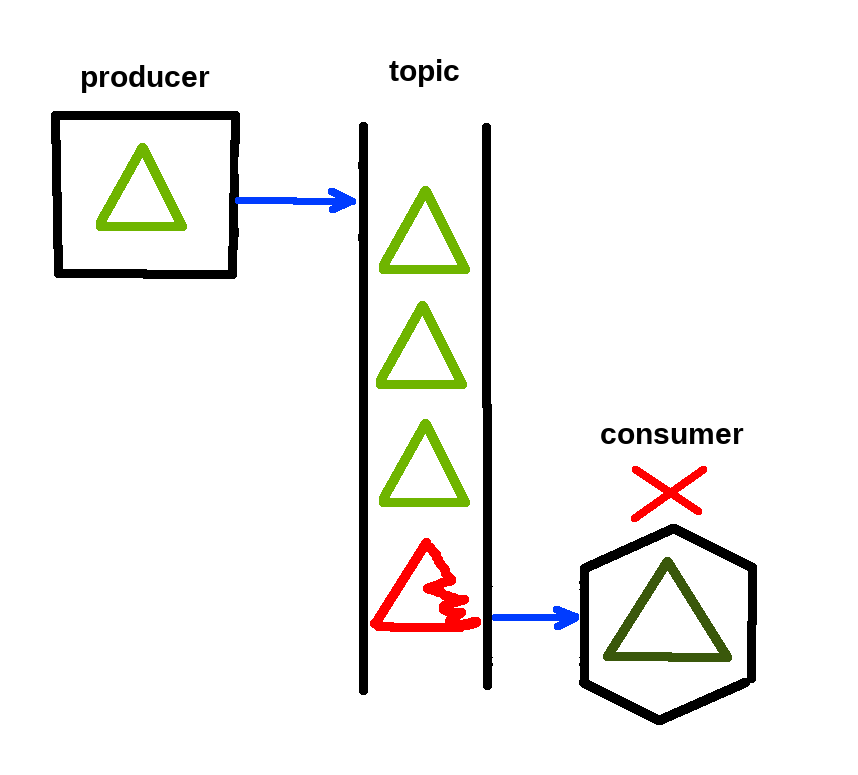
Well, this message will stay there and will crash your consumers (services that listen to certain messages in this topic). Consumers will try to read the faulty message and of course fail with some error.
- 1. Read message.
- 2. Try to parse it.
- 3. Crash (commit no offset, because service crashed).
- 4. Go to step 1. and read again the same faulty message ad nauseam.
This is in fact a serious problem and I have experienced it many times. There are few strategies to act in such case:
1. Skip the message
It means that you can reset or change the offset of the specific topic + consumer group (Kafka remembers offsets as pointers in the topic per some group of consumers reading from the same topic). When faulty message is at the offset 73, you can tell Kafka to just call it a day and go directly to offset 74.
How to do it?
1 ./kafka-consumer-groups.sh --bootstrap-server localhost:9094 --reset-offsets --new-consumer --group my.group --topic my.topic --to-latest --execute
Drawbacks: Well, the message is still there and when you try to read the topic from the beginning, you will have the same problem again.
More bad things: It's easy to seriously mess, because you can skip more than expected. Don't even try it on prod!
Extra bad thing with catch*: see the green block below.
I would say that skipping the message is acceptable when you experiment on some kind of sandbox environment and don't want to delete the topic. It's fine to just ignore one message and continue testing. However when it comes to the real production system, it may be too dangerous to skip the faulty message, because the problem will likely manifest itself in the future. It's like setting a trap for maintainers of the system. From the other hand the solution may work well if you have very short retention policy and you expect that:
- Message will be deleted after few days anyway.
- Message will be compacted (unfortunately it's harder to predict exactly when it will happen).
2. Spawn interim (temporary) service to process the message
I work with microservices and my consumers are small applications that can be easily created and deleted on demand. It's possible to write a modified version of consumer to deal with the faulty message. The modified service will consume the message, try to do best thing that is possible and commit the offset to the next one.
Drawbacks: Still, when re-reading messages from the topic, the service needs to be there to consume the faulty message, otherwise will have the same problem again.
I would say that this solution is preferable for the real production systems under certain conditions. Temporary service will be perfect if you care about the data in the message (it may be for example part of the financial transaction). You can copy the original consumer service, modify the code and be able to transform the incorrect message format into correct one. Yet, the message will be still in the topic, so next time you read all messages, someone will need to spawn the temporary service again.
3. Modify the code permanently to always be able to parse the message
Are you missing one field or value in the message? Maybe you can provide default value for the missing field. If this is unacceptable, then add a pretty if statement to match the exact faulty message.
1 if message.important_attribute == 'faulty' and message.id == '1234':
2 # Perform some logic
3 commit_offset()
Drawbacks: Seriously, you probably don't want to do this. How many of those statements are you able to add? You'll create real minefield for future developers.
This solution is fine for cases when you have a systematic problem of specific kind. A producer service had bug and emitted thousands of messages with wrong format or missing piece of data. If problem is wide, then the responsibility should be shared with consumer service. It will work for easily fixable problems as long as the code modifications won't obfuscate the code. I personally think that code readability is a key to successful software development and in many cases it's more important than the performance.
4. Delete the topic
Things gone really bad. You have millions of faulty messages in the topic and there is no hope to fix that. You can save the whole company from disaster only in the following way: You consume all messages from the old topic "shopping.cart", then you feed them through some kind of filtering/fixing service to the newly created topic shopping.cart.v2. New topic will contain only the correct data. Yes.
Drawbacks: It's for sure more difficult to perform this operation of transferring data between topics. Also please take into consideration that this may take hours to complete!
What is my suggestion about best way to deal with faulty immutable message?
Mistakes and bugs happen, so in the end you'll need to do something about the erroneous data. Please make sure you choose the solution that will be sustainable and will not just postpone the problem, so the next person working with your Kafka-based system doesn't get upleasant surprise in the next 7 days. Well, of course it's best not to make mistakes at all and be extra careful with your data. Use unit tests, code review and try to anticipate errors at the stage of planning!
Did you know?
It's tricky phenomenon, but it's worth to mention that resetting offsets in Kafka works a bit different than expected.
1. Take a topic with faulty message in it
2. Reset the offset to "skip" the bad message
3. Everyone is happy and cheerful, but after 7 days the message comes back! This is normal behavior for all consumers that have
1 auto.offset.reset: earliest
setting. And yes, it's pretty confusing, because you expect the offset to be committed permanently on specific consumer group. In fact the problem is just postponed for 7 days! This problem will affect only consumers that received no new messages for the last 7 days. It's good to know that.
References:
Kafka JIRA ticket to increase the retention to 7 days